
Okay - did I ever pick a great week to go hang out at an old military installation with no internet so I could focus!
First off, before I get too excited, is this real? I mean, can I download like 19,000 plasma proteomes?

FUCK YES I CAN! I just don't have anywhere near enough hard drive space for 20,000 SWATH FILES!

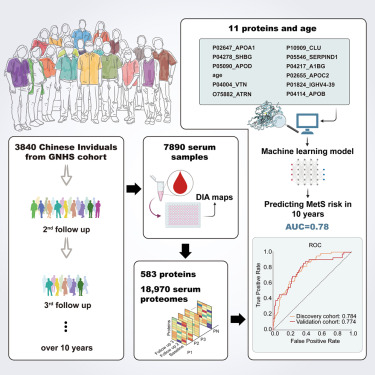
Gradient looks like around 20 minutes using an Eksigent trap/elute system running around 10 microliters/minute. Probably given the trap elute I'm guessing around 25-30 minutes per sample. Variable window DIA with 50 windows. TRACKING A LONGITUDINAL COHORT OF LIKE 4,000 different people with multiple sampling events over 10 years! So so so so cool.
Get this. They processed it all with DIA-NN using a library of only around 800 proteins from their library. Absolutely makes sense. But can you imagine how much more can be mined out of this as DIA algorithms continue to evolve? Re-mine this in 5 years when the algorithms are faster and computers are way way faster and you can actually consider a much larger and deeper depth of human protein expression in plasma! The kind of goldmine for protein biomarker discovery we've been dreaming of and little birdies keep telling me there are a bunch more on the way. It's just that things like these take a long time to do!
Very interesting on the subset library approach. They effectively do targeted proteomics on a longer list. To maximize that I think encyclopedia is actually a better algorithm where you get a full grid array output. All that said, I’m a bit weary of FDR here. If the target feature space is incongruent with the discovery space, I am not convinced that diann is the best algorithm. For the same reason, cancer plasma sets should probably have some of the host cancer leak proteins included in library but also to prevent false positives forced on the unmatchable signals. Maybe the complexity match changes since this is serum and not plasma, but Astral is achieving over 6000 protein ids with diann on Seer enrichment platform (bias here, I work for Seer).
ReplyDelete