If I'm flipping through my hand held digital phone thing and the Twitter icon looks like this

...it generally means that I did something wrong. To combat that anxiety I just don't open Twitter for a while. Turns out a lot of the these notifications had to do with Monday's ULTRA-FAST proteomics paper and subsequent blog post.
While most of these were really funny suggestions on the names of faster methods, a lot of smart people looked at this study and found it a little less impressive than first glance.
First of all -- 5 minutes isn't anything remotely close to the run to run time. It looks like sample to sample on this system you're talking about 17.5 minutes. Which, hey, sometimes your HPLC is really super slow and maybe you just need a faster loading HPLC for the next stage, but 17.5 minutes is ~82 samples per day.
There is a Bekker-Jensen et al., paper from 2020 that did some even UltraFASTER samples/day on a FAIMS Exploris 480 that realistically got pretty similar data.
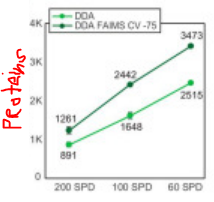
To be clear, I'm not putting down the UltraFast paper at all, but I do think that from a practical sense, this title might not be the most helpful thing in the world.
If this group gets 10,000 samples shipped to them and their collaborators expect that data back in the 35 days it would take to run them all based on the 5 minute gradients, there might be some fallout when they have to explain why it took an extra 3 months (excluding QCs and blanks and calibrating the instrument, etc.,)
No comments:
Post a Comment